
三种场景
tcpcopy+intercept是一种常见的做压测的技术,同样基于它的原理,我们也可以用来部署waf,即利用tcpcopy+intercept将http请求转发到waf机器上,来实现几乎无业务影响的旁路部署技术。
我总共遇到了以下三种场景:
- 传统网络架构;waf+intercept分别部署服务器
- 传统网络架构;waf+intercept部署同一台服务器
- 阿里云vpc网络;waf+intercept部署同一台服务器
在这个过程中,两种网络特点、两种业务场景下就会有不同的方案。
传统网络架构提出来主要是和阿里云vpc网络做区分。在传统场景下,所有服务器及路由器均有虚拟化服务器承担,而vpc网络中,二层三层的配置都要看阿里云的实现及结构,而一些不同的点给我们的方案带来了一些适配上的挑战。
传统网络架构下waf+intercept分别部署
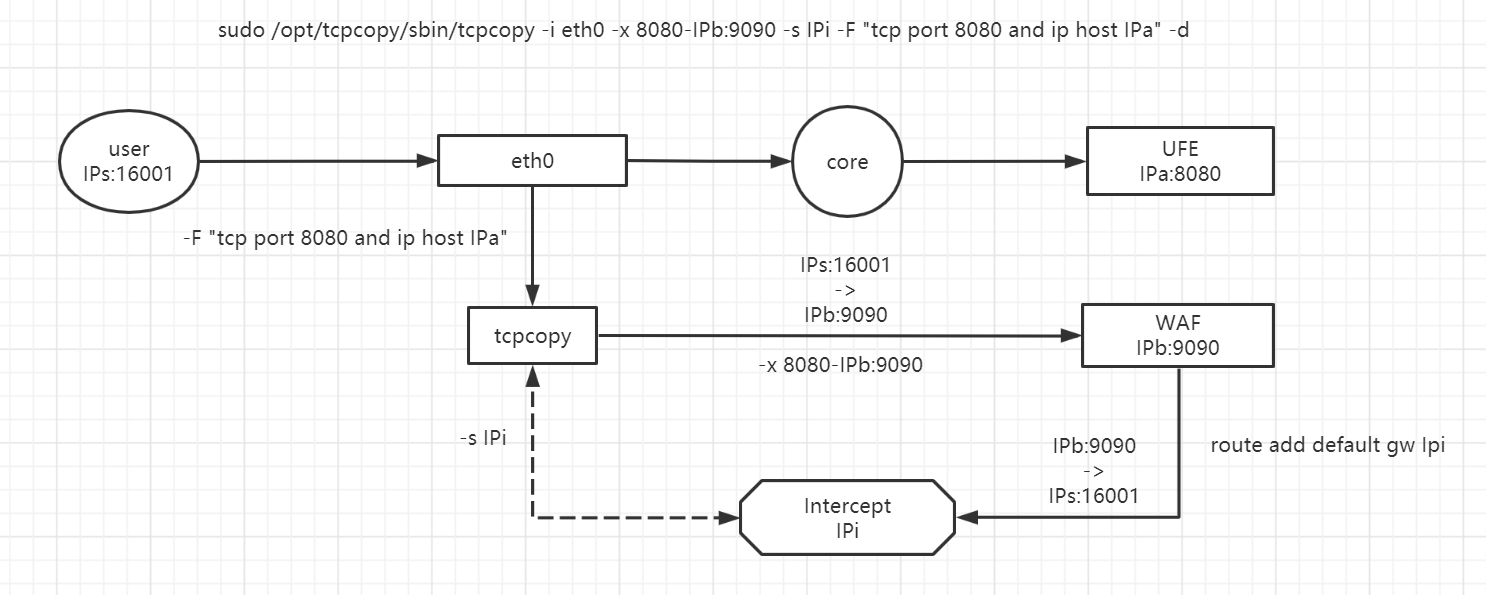
假设有一个user的IP为IPs,向nginx服务器的8080端口发起请求,eth0网卡接收到了该请求并经由内核过滤,最终交给UFE去处理。
1 | -i eth0 -F "tcp port 8080 and ip host IPa" |
tcpcopy实际上架在eth0上,按上图匹配host为IPa,且端口为8080的流量。
1 | 8080-IPb:9090 |
保持源端口不变的前提下,把流量转给IPb的9090端口,IPb为waf的机器。
1 | -s IPi |
指定intercept的IPi。
1 | route add default gw IPi |
在waf机器上配置一条默认路由,把即将发送的数据包指向intercept所在的机器地址。
这样tcpcopy在传统网络里就可以正常工作了,接下来分析一下这个场景下各个组件的必要性和踩过的坑。
intercept的必要性
最开始做的时候,配完了也就完了,没有去思考intercept的原理。从经验来讲,按照我们对TCP三次握手的经验和理解,可以仔细拆解一下这个流程。
正常的数据包交互过程。本文的IPs指的是来自用户的IP,IP-source。不是指网络安全组件。
- IPs->IPa SYN
- IPa->IPs SYN.ACK
- IPs->IPs ACK
- IPs->IPa GET
- IPa->IPs RES
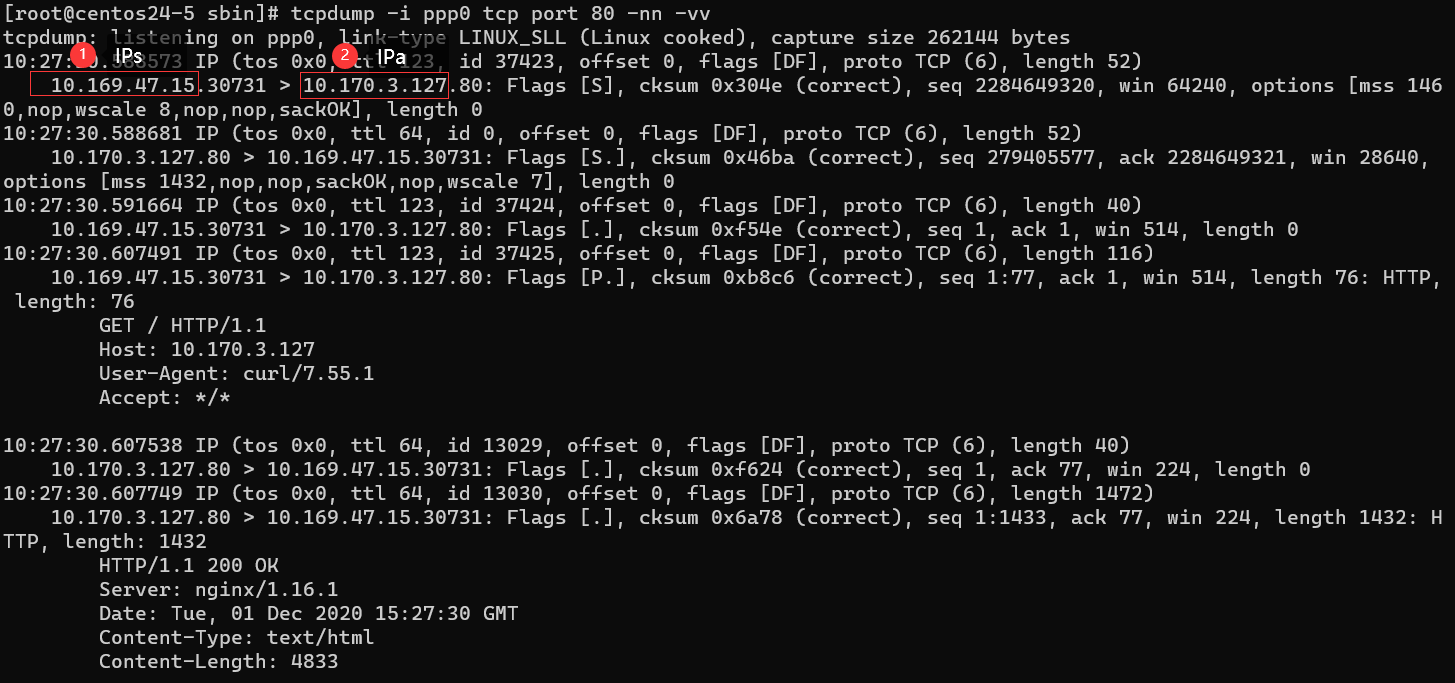
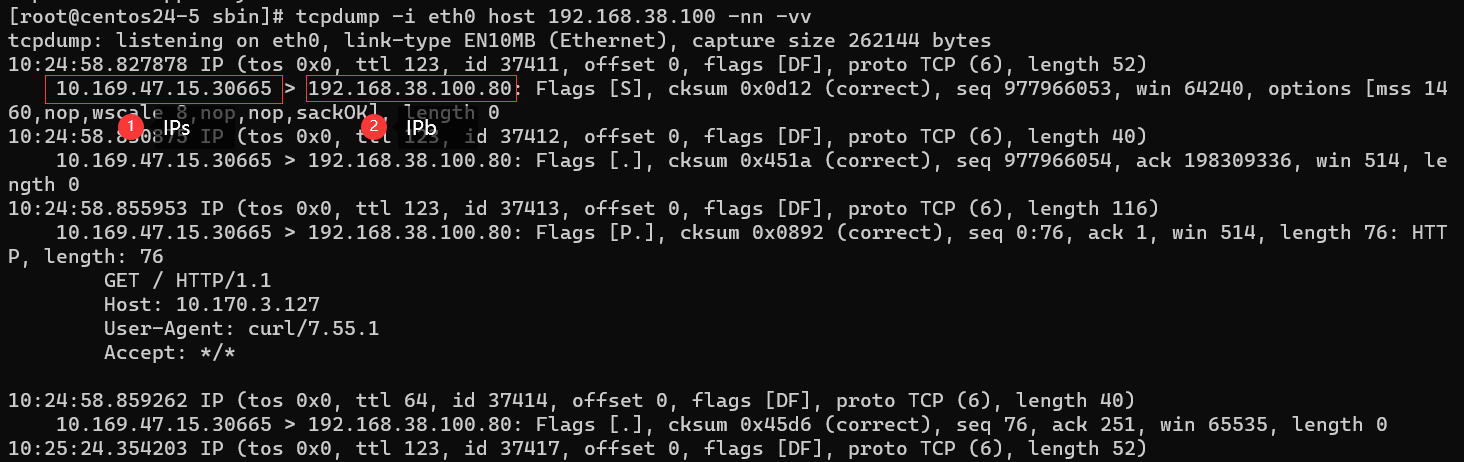
上面第一张图是IPs访问IPa的正常业务的数据包交互过程。
上面第二张图是tcpcopy做的转发后变成IPs访问IPb的数据包交互过程。
tcpcopy在做流量转发时,首先转发第一个SYN包,第一个数据包就变成了
- IPs->IPb SYN
waf看到了这个数据包,会进行第二步握手
- IPb->IPs SYN+ACK
由于默认路由的关系,这个包会由waf路由到intercept所在的机器。此时intercept会把第三次握手要回的信息告诉tcpcopy,由tcpcopy再做ACK确认包来完成TCP的连接,从而可以进一步copy GET请求发送给IPb,否则协议无法完成。
在这一步,只有intercept接收到了第二步的SYN+ACK,知道第三次的ACK应该回复什么,所以只有它可以告诉tcpcopy要回复的内容,再由tcpcopy来完成三次握手,发送最后一步ACK,并接着发送GET请求。
路由配置的必要性
在不配置路由的情况下,waf接收到了来自IPs的握手包,那么SYN+ACK包会直接沿着原路由路线发送回IPs,如果IPs在本机抓包的话实际上是可以看到两个SA包,一个来自nginx,一个来自waf。
传统网络架构下waf+intercept部署同一台机器上
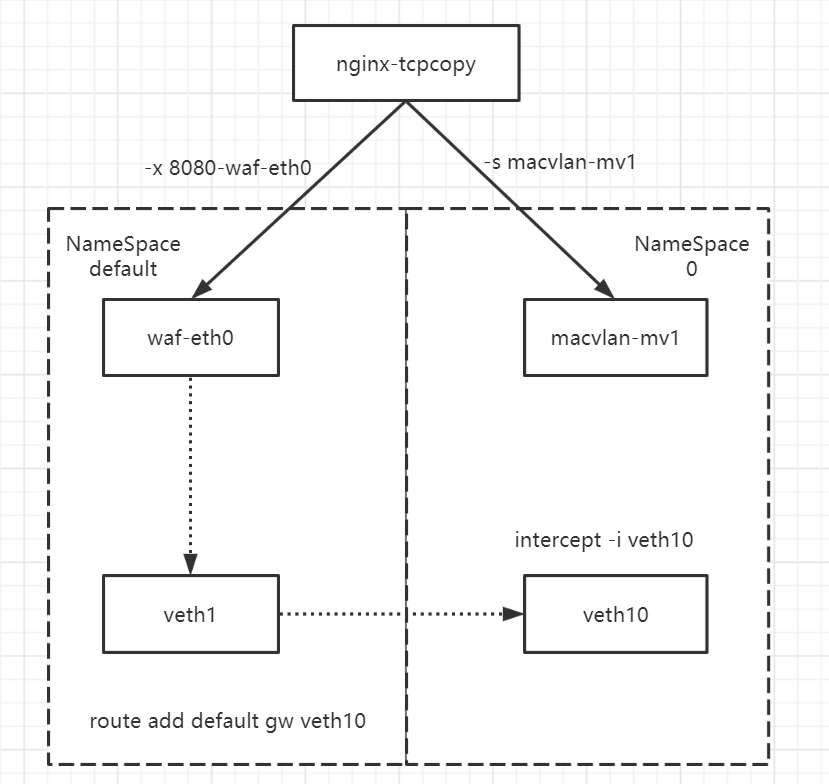
方案特殊的地方在于要把waf和intercept放在一台机器上,在这个场景下要做到的事情是:
- 在tcpcopy看来,发给waf地址和intercept的地址需要是两个IP
- waf机器需要把默认路由设置指向intercept的地址
在这种情况下,选择了macvlan虚拟一块网卡的方案,然后创建一个网络命名空间NS0, 把macvlan网卡放进这个网络命名空间。
在这个场景下遇到的限制是实际上macvlan和父网卡是不能通信的,所以通过创建一对虚拟网卡对veth1-veth10,把veth10放进NS0空间,然后把eth0网卡的流量默认指向veth10,然后在NS0的网络命名空间下,监听veth10网卡。
达到的效果是,tcpcopy看来,它在跟mv1通信,在eth0看来,他通过veth1在跟eth10通信.
不使用ipvlan的原因是,在ipvlan的场景下,eth0相当于一个路由器,ipvlan的地址实际上不能直接跟tcpcopy通信。
使用Ubuntu16.04
设置父网卡为ens3,创建一块macvlan的网卡
1
ip link add mv1 link ens3 type macvlan mode bridge

创建veth网卡对
1
ip link add veth1 type veth peer name veth10

创建namespace
1
2ip netns add ns0
ip netns show
将mv1和veth10放进ns0空间里去
1
2ip link set dev mv1 netns ns0
ip link set dev veth10 netns ns0
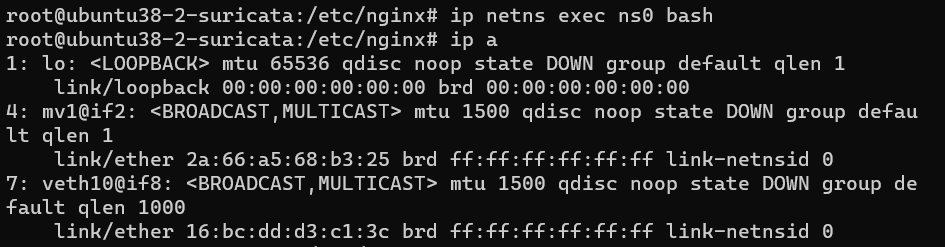
在主命名空间里,给veth1配上ip,veth1和veth10在一个网段里即可
1
2ifconfig veth1 192.168.100.100/24
ip link set veth1 up

在ns0里,给veth10和mv1配上,mv1保证和eth0在同一个网段即可
1
2
3
4
5ip netns exec ns0 bash
ifconfig veth10 192.168.100.200/24
ifconfig mv1 192.168.24.100/24
ip link set veth10 up
ip link set mv1 up
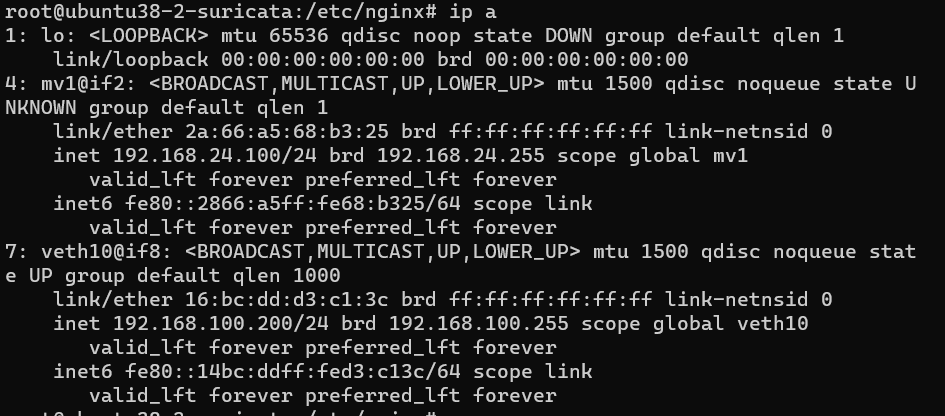
验证从nginx来ping mv1的地址
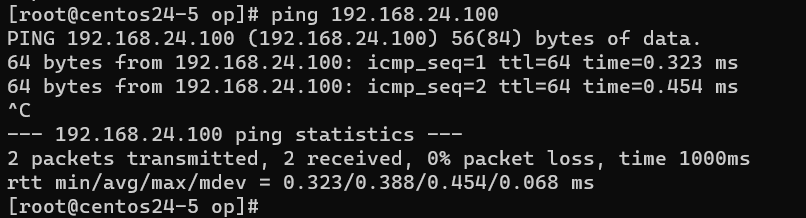
验证从eth0来ping veth10的地址

设置默认路由为veth10的地址 via地址
1
route add default gw 192.168.100.200

在ns0中运行intercept并监听mv1地址
1
2ip netns exec ns0 bash
./intercept -F "tcp port 80" -i veth10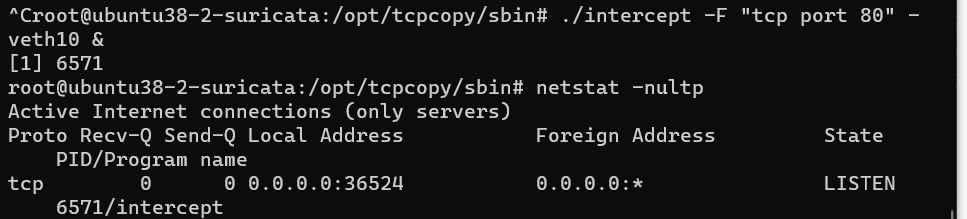
在nginx上运行tcpcopy
-x指定发送给waf-eth0的80端口
-s指定intercept为mv1的地址192.168.24.100
1
/opt/tcpcopy/sbin/tcpcopy -i ppp0 -x 80-192.168.24.2:80 -s 192.168.24.100 -F "tcp port 80" -d
此时测试给nginx发包,可以在不同网络位置上抓到不同的内容
在waf-eth0上可以看到sip为用户,dip为waf-eth0的GET包
在ns0中的veth10上可以看到由waf-eth0返回给sip的包,intercept在这里做了拦截
在mv1上可以看到nginx与mv1-IP的通信包

横向扩展
后续扩展只需要在nginx上运行tcpcopy即可,指定同一个waf和同一个intercept
RP_filter配置的大坑
在这里记录一个BUG的解决过程,算是踩过的一个坑。
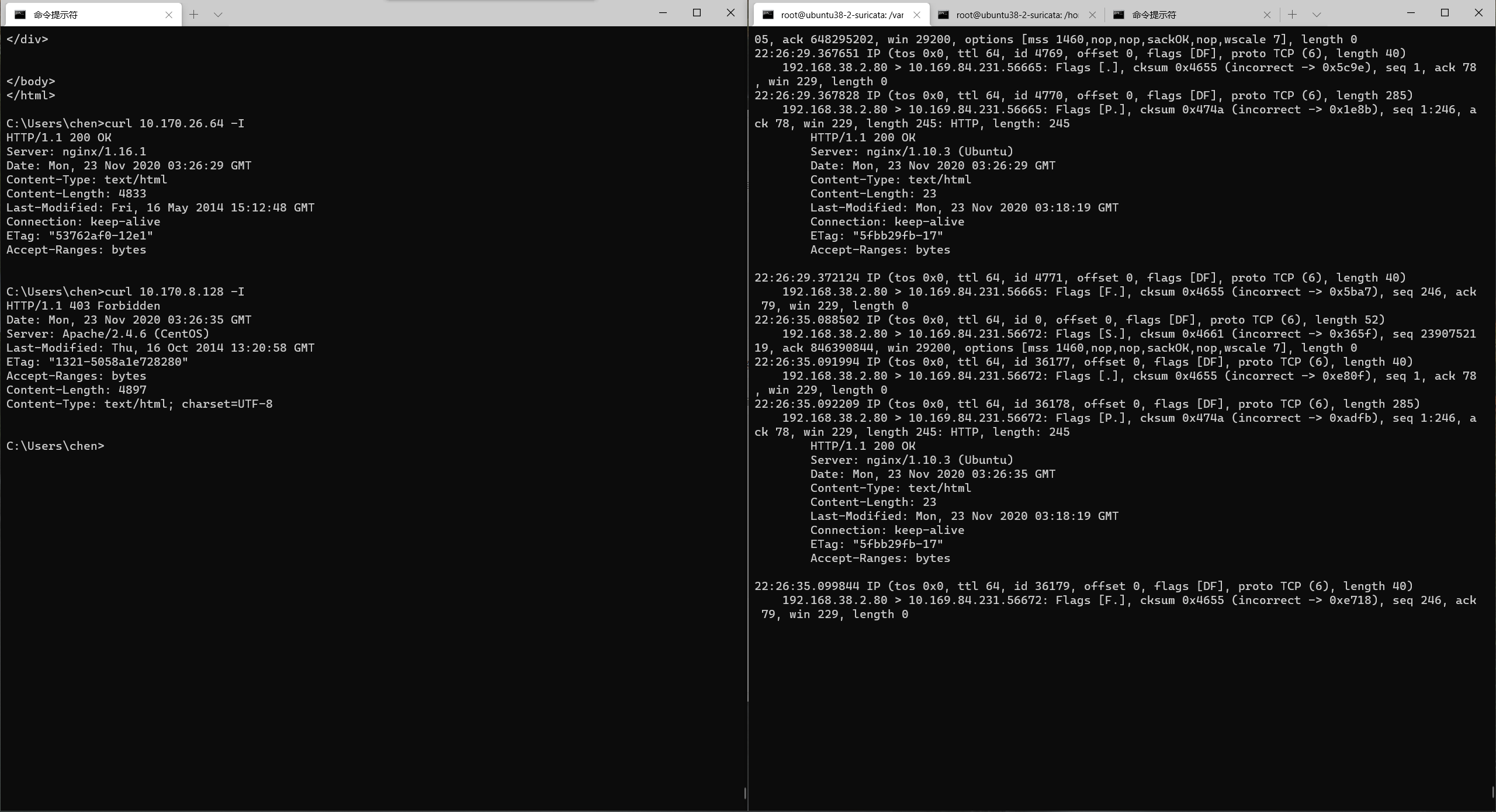
首先我们按照上述过程配置好各个组件,并将他们正常连接。首先作为IPs,测试给IPa发包,并且在waf机器上抓包,可以接收到来自IPs的SYN包,这说明tcpcopy是正常工作的,但intercept机器没有接到waf的包。
- 没有产生or没有发出去?这是一个哲学问题,从waf接到这个SYN包,到产生SYN+ACK,到intercept接收到这个包,中间我们从后往前逐步debug验证。
waf-eth0网卡上没有看到发出去SYN+ACK包,这说明包不是丢在链路上,也不是被BPF层面的iptables firewall规则给拦住了。
waf-eth0网卡确认接收到了SYN包,通过tcpdump抓包可以看到,那么为什么不产生返回包呢?
推测1: 这块网卡坏掉了,接收到SYN就是产生不了返回包?
验证: 在同网段CURLwaf-eth0网卡的80端口,可以建立正常的连接; 换了一块网卡来接受流量,现象是一样的。说明网卡正常,再提取问题特征为,网卡处理IPs->IPb的包处理不正常。
推测2: 网卡把这个SYN包丢了?可能导致网卡认为这个包是坏的然后把它丢掉?
验证: 用wireshark down下来了所有的由tcpcopy转发的通信流量包,从链路层到IP层到TCP包,逐行看timestamp,TTL,也没发现啥问题。
推测3: 既然网卡正常,包也正常,而现象是特定流量特征的包会被丢掉,那么还有一种可能是,在BPF层面还是有规则做了这种过滤。
验证: 做了一个对照组,产生这种问题的系统版本是Ubuntu 16.04 LTS.而同样的问题在centos7.2上并没有发生,这加大了这个推测的可能性。
查了大量资料发现了内核原来还有个配置叫做: RP_filter。
具体的配置细节可以参考链接
在Ubuntu默认配置为
1 | net.ipv4.conf.all.rp_filter=1 |
在centos下默认配置为
1 | net.ipv4.conf.all.rp_filter=2 |
当这个配置为1时代表:开启严格的反向路径校验。对每个进来的数据包,校验其反向路径是否是最佳路径。如果反向路径不是最佳路径,则直接丢弃该数据包。所谓反向最优路径的一个场景就是,接收到包的网卡和响应数据包出的网卡如果不是同一个网卡,则判定不是最佳路径,就会把包丢弃。而在waf和intercept在同一台机器上的场景下,流量从eth0进,从veth出,就会刚好匹配到这个坑,所以其实如果我们不做这个场景下的实验,其实是学不到这个层次的知识的.
阿里云vpc中waf+intercept部署同一台机器上
这个场景下,在我们已经部署好环境,且保证前面踩过的坑都搞定下,又延申出来几个有意思的小坑.
- 阿里云不支持用户自己虚拟网卡
在一个阿里云经典vpc网络中,172.16.0.253一般为网关地址,网卡通过dhcp向网关注册拿到IP地址,当我们虚拟出一个网卡时,即使用这块网卡的mac向网关发起dhclient请求,也拿不到地址.如下图我们主网卡的地址为:00:16:3e:16:c7:da,虚拟网卡的mac地址为4a:29:7b:47:45:4a,网关面对不同的mac也不会正常响应dhcp请求.
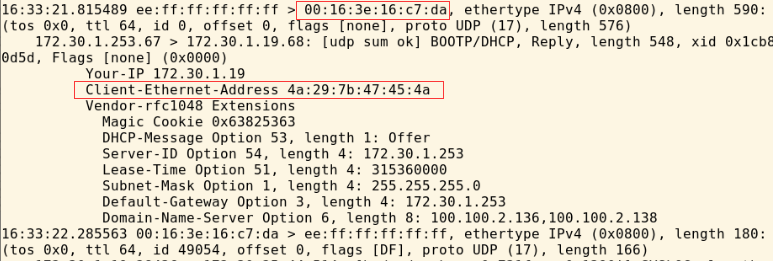
在搜集各种解决方案,也同时提交了工单,得到的回复是需要阿里云是不支持用户自己虚拟网卡的,扩展网卡的方式是在控制台添加弹性网卡,根据不同的ECS规格其实可以绑不通数量的网卡,这样的网卡作为一块同网段的物理网卡绑定在网络空间里.
- 适配路由需求
在客户公司的部署方案中,所有的机器是通过jumpserver来管理,而恰恰jumpserver和该机器不在同一网段,一旦把宿主机的路由规则改了,jumpserver就连不上来了,这也是一个新的挑战.
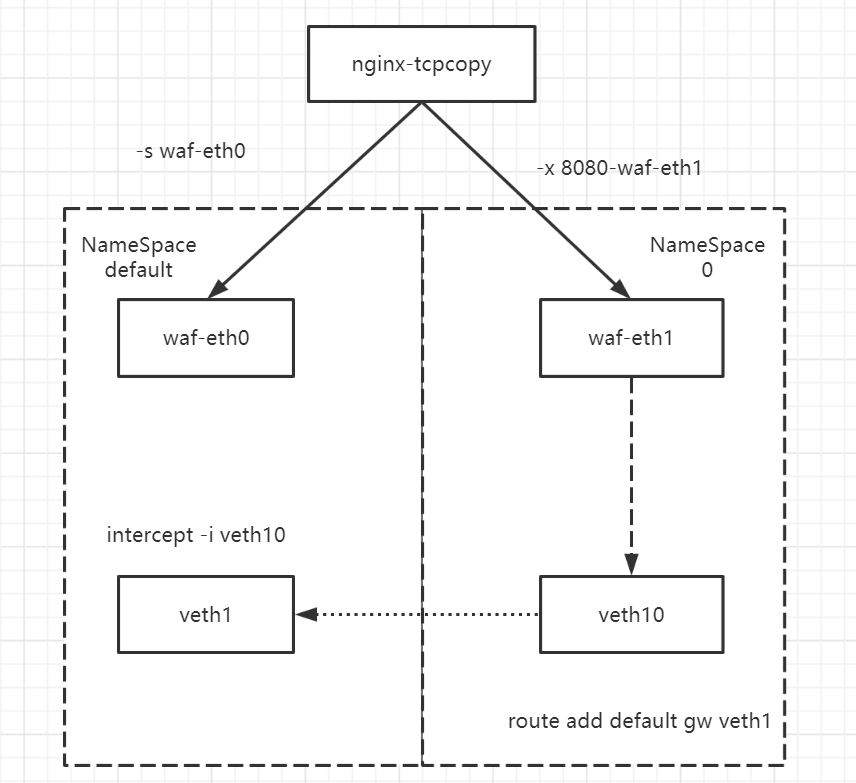
解决方案: 我们调换了intercept和waf监听端口的网卡,做法如下:
保证改了路由以后jumpserver可以正常通过waf-eth0主网卡来管理连接机器不影响正常的工作.
- 选择让waf开在NameSpace0里,tcpcopy指定waf的地址为eth1的地址.
- 在NameSpace0里,指定路由方向为veth1
- 在NameSpace-default里,把intercept开在veth1上,但tcpcopy指定的-S仍然是eth0的地址.
- 检查阿里云安全组规则
在以上方案都走通的前提下,我们又遇到了tcpcopy发出流量,但接收网卡接收不到的问题,排查了iptables等问题以后,最终定位到阿里云安全组入方向罪恶的事情,改了以后也没有什么太大的问题,就过了.
安装waf,tcpcopy,intercept,SYSlog,LogStash等记录
ubuntu搭建modsecurity
第一步:安装libapache2-modsecurity模块及其依赖包
1 | apt-get install libxml2 libxml2-dev libxml2-utils libaprutil1 libaprutil1-dev libapache2-modsecurity |
我们可以使用以下命令查看一下modsecurity的当前版本
1 | dpkg -s libapache2-modsecurity | grep Version |
第二步:配置modsecurity,启用拦截模式
1 | service apache2 reload |
该命令生效后,会在/var/log/apache2/目录下生成modsecurity的日志文件modsec_audit.log
1 | 修改SecRuleEngine On |
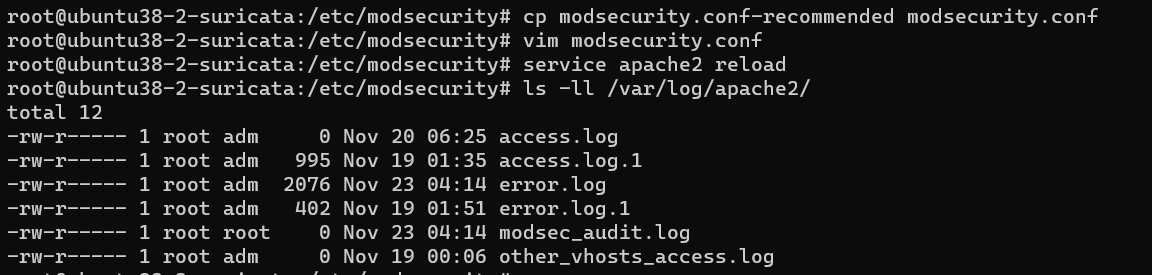
第三步:启用规则
1 | cd /usr/share/modsecurity-crs/base_rules |
第四步:启用modsecurity模块
1 | a2enmod headers |
第五步:测试真实的攻击payload,在tcpcopy的场景下
1 | curl "10.170.28.173/?id=%3D1%20and%20ord(mid((select/**/concat(username,0x3a,password |
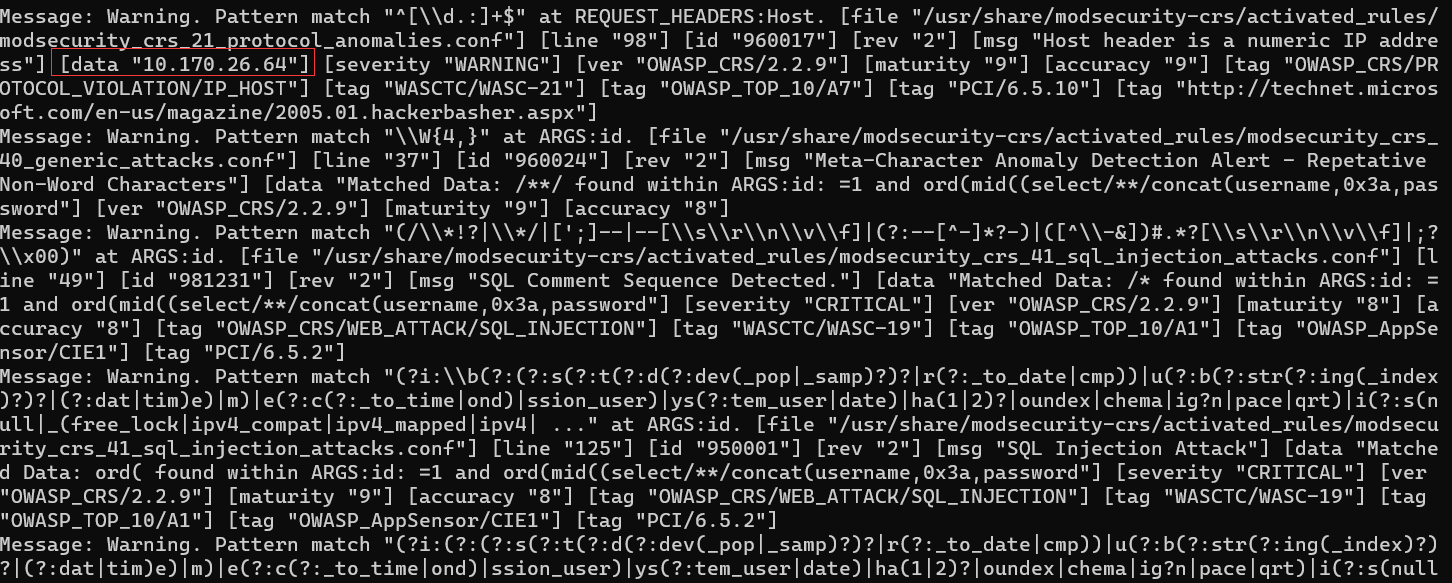
modsecurity接ELK
第一是把syslog同步到SOC中心去,第二部分是在ELK上解析modsecurity规则。
syslog同步
加一条去往SOC的路由,之前因为要把tcpcopy的流量通过默认路由打到网络命名空间Namespace1去,所以直接路由是不通的。
写去往SOC的路由规则,掩码为32,从网关处走
1
sudo ip r add 39.97.224.7/32 via 192.168.7.1
使用rsyslog同步的方式,把本地的log打到soc中心,下图为rsyslog-client配置
1
2
3
4
5
6
7
8
9module(load="imfile" PollingInterval="10")
input(type="imfile"
File="/var/log/apache2/modsec_audit.log"
Facility="local2"
Severity="info"
tag="XD"
)
local2.* @39.97.224.7:514
local2.* @192.168.38.1:5141
2server端配置
if $syslogtag == 'XD' then /logs/xd.log
LogStash配置处理
soc中心需要做两件事,把syslog自带的TIMESTAMP/HOSTNAME/TAG去掉,并不影响原来的格式,这里存在一个发送端和接收端,考虑到发送端应该尽可能地保证发送日志的量完整,再由接收端自己切割日志为想要的格式,所以先用一层logstash切掉多余内容,再用logstash-modsecurity.conf处理alert日志。
下为logstash先处理TIMESTAMP/HOSTNAME/TAG一层的配置
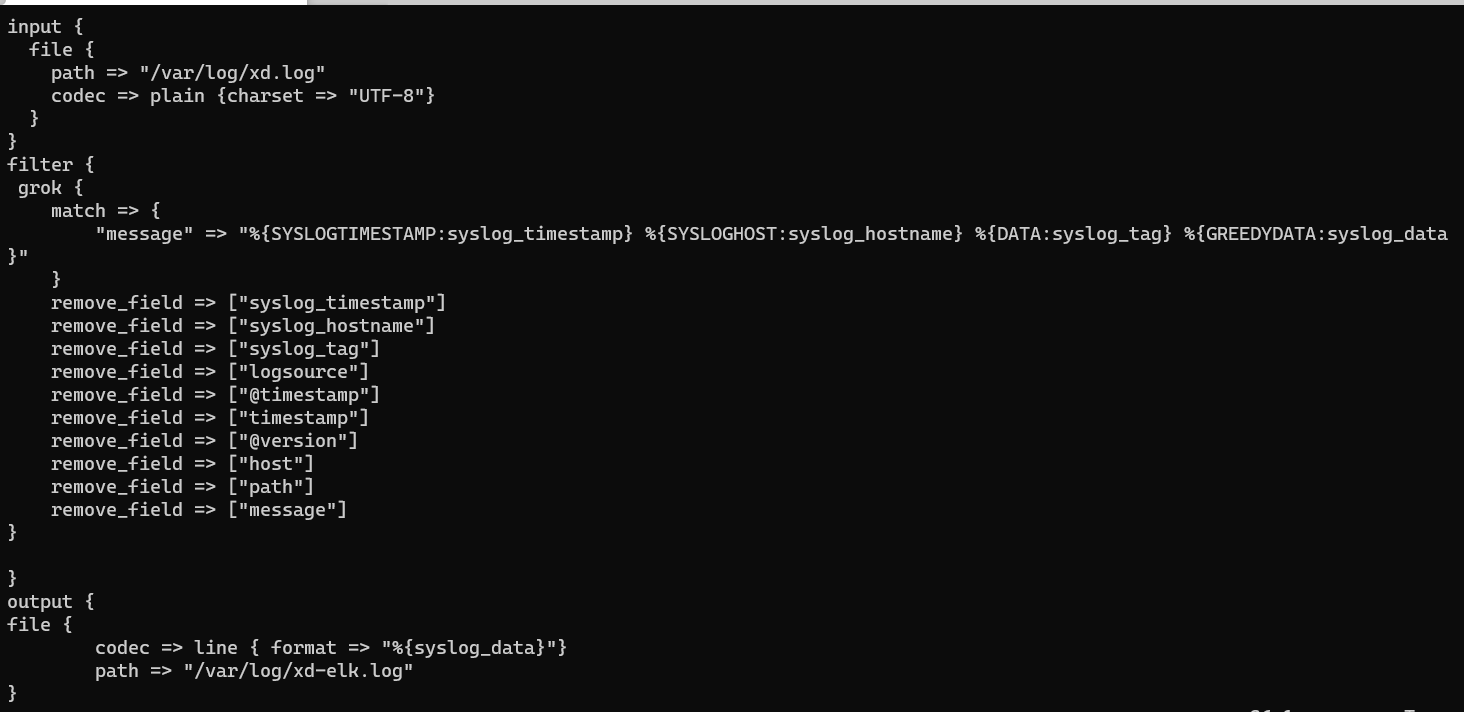
pipeline配置*.conf,以及修改1010_input和3000_output到es里
1
2
3
4
5
6
7
8
9
10
11
12
13
14
151010_input
path => "/var/log/xd-elk.log"
3000_output
output {
# file {
# path => "/var/log/logstash/msjs.log"
# }
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "waf-%{+YYYY.MM.dd}"
}
}
pipeline
- pipeline.id: waf
path.config: "/opt/logstash/config/conf.d/waf/*.conf"
编译安装intercept
1 | git clone https://github.com/session-replay-tools/intercept |
编译安装tcpcopy
1 | git clone https://github.com/session-replay-tools/tcpcopy |
撤销更改与回退
del网卡及命名空间
删除veth网卡对,及从命名空间中释放网卡
1 | ip link del veth1 type veth peer name veth10 |
kill tcpcopy
1 | ps -ef |grep tcpcopy |