
背景问题
场景如下:一台40G硬盘大小的阿里云日志服务器,每天日志成长量大约为2~3G,经常因为硬盘满了导致ELK服务异常或者挂掉,因此要解决问题,其实就是维护管理磁盘的问题。
日志流向
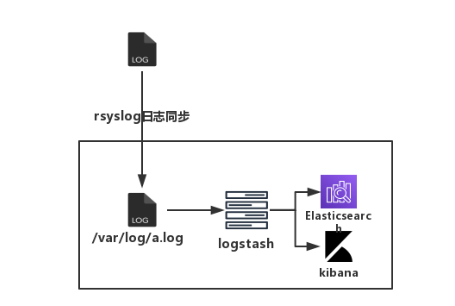
该拓扑较为简单,本地log和远端log做同步,然后通过Logstash进行日志分类,Elasticsearch做索引,kibana做展示
寻求原因
磁盘经常被占满有两个原因,一是日志存储,二是索引生成,三是message文件过大。因此清理手段也应从这两方面入手,比如说我只要保存两个星期的内容,那么日志存储的粒度应该定为天,索引也要以14天为期限清理一次。在/var/log里,message文件会记录系统开机后的报错信息等,当ELK崩掉之后,大量保存会存储在message文件里,导致该文件数量级过大。
日志分片存储
日志存储分为两个阶段,第一个阶段是日志同步存储,这里可以用logrotate做日志切片,如下配置:
1 | /var/log/a { |
logrorate配置说明
daily是更换的时间间隔
rotate指一共进行多少次更换,就是保存多少次删除最旧的那个,这里的设置是指删除10天前的
missingok是忽略错误存储
notifempty如果日志文件为空,轮循不会进行。
通过工具配置将同步存储限制在10天以内,这样最多也就20G左右。
这样切片之后,存储的文件命名就改了,因此logstash的input也得改,但改了之后发现切片后的log创建者不对,本来是elk用户,但现在创建者变成了root,因此logstash就读不了,因此需要创建指定权限的log,本来在conf里面已经写了:
1 | create 0644 elk elk |
但不清楚为什么创建出来的文件还是root用户,因此暂时就用root用户启动logstash
logrorate手动运行,任意时间都可以手动运行
1 | logrotate /etc/logrotate.conf |
logrorate日志记录,记录它本身的运行情况
1 | cat /var/lib/logrotate/status |
logrorate的定时任务
1 | cat /etc/cron.daily/logrotate |
第二阶段,在logstash里还需要做一下分时间片存储,不然原日志删除了,处理后的日志不断累积也会导致磁盘被占满。
在logstash的config里面配置如下:
1 | output { |
这样就可以把处理后的日志也分片了,压缩之后日志存储比较小,每天就十几兆,因此短期内也不用定期清理。
倒排索引
很好奇为什么ELK的索引占用空间这么大,原来是使用了倒排索引的存储技术,即和谷歌百度这类搜索引擎类似,颠覆了key->value的传统存储,反而是从不同的value->key的索引,比如说如下的一行日志(没有截全):
1 | geoip.city_name:Beijing geoip.country_name:China dip:10.130.1.205 sip:210.13.40.225 parameter:proc=4&isAjax=true&isAir=undefined |
在elasticsearch中会被拆成如下JSON数组: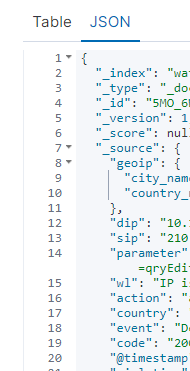 d
d
正因为存储了这么多的索引,才能通过查任意字段找到原日志条目,所以占地方。
ELK提供了一个删除索引的接口如下:
1 | curl -XDELETE 'http://127.0.0.1:9200/*2019.10.1*' |
因此把这条命令扩展到shell脚本里,实现一个定期删除的功能就可以了。
1 |
|
crontab加一下就可以
1 | 0 6 * * * /bin/bash /opt/xdel.sh |
message文件
messages文件用来保存系统错误,elk出现问题后,报错会叠加,这样就会导致日志报错很大。配置文件在/etc/rsyslog.conf里有这么一行:
1 | *.info;mail.none;authpriv.none;cron.none /var/log/messages |
日志定期删除对系统维护不好,出了问题也没法回溯,所以要进行回滚的设置和定期保存。
微信监控
即使做了以上处理,还是需要了解一下磁盘占用情况,但又不可能天天上去看log,这里采取企业微信api调用的方法与服务器进行联动,从而实现推送和拉取两条路线的信息获取功能,具体内容见下一篇。