
一、 背景
在百度搜索我的目标关键词的时候,本来找的是目标公司的内容,但是意外地发现了一些菠菜网站的链接,百度快照里的内容和我的目标公司首页内容一致,本着感性趣的态度点进去,看看是什么
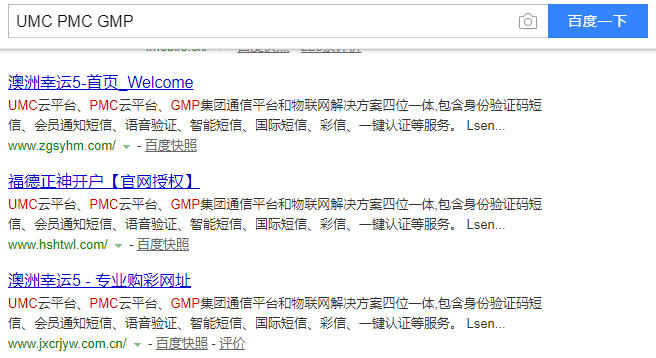
大都是一些菠菜网站,这里列出几个网址,大家警惕:
http://www.zgsyhm.com/
https://www.fd3344.com/home/
那么问题来了,这些菠菜网站挂着这些毫不相干的pages干啥呢?
二、分析过程
2.1 判断是否为服务器被黑
根据以往遇到的情况,拍脑袋会认为服务器被黑了,然后直接跳到黑页这里,随即看了下他们的IP,发现都是阿里云香港,对比着目标公司的IP,发现并不一样,这条排除
2.2 判断是否是首页的JS跳转
那就很有意思了,那想着会不会是JS渲染+跳转,以前也遇到过这种,相当于披着一层衣服的菠菜
正常地进行了单步调试抓包模式,发现基本的访问流程都是这个样子
首页 -> js跳转-> 菠菜网站
直接F12,一个首页的源代码如下: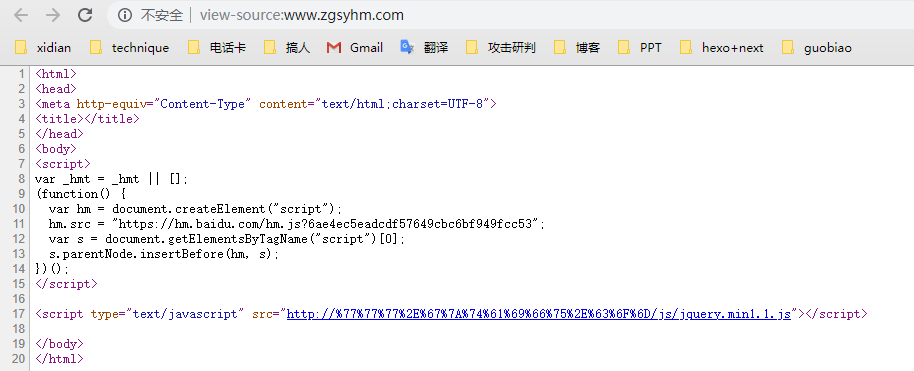
1 | URL解码之后是: https://www.gztaifu.com/js/jquery.min1.1.js |
这就说明确实是JS跳转,但是首页上并没有我查的目标关键词,那么问题来了,到底是什么原因导致菠菜快照上的内容和实际内容不一致呢?
2.3 推测菠菜的思路
这里我一开始是没有想出来的,请教了一个对灰产有研究的朋友,他说这种情况一般是正常公司首页被爬去给菠菜做伪装,这句话点醒了我,于是我整理了一下当前的信息:
菠菜主要目的:披一层衣服,避免被发现
菠菜最容易被发现的入口:百度、谷歌等很容易被监管部门找到的搜索引擎
菠菜最需要防御的对象:robots爬虫,百度快照的内容生成也是通过spider爬出来的,因此例如百度Spider、搜狗spider等是菠菜最怕的东西
这就很清楚了,接下来我去验证一下自己的猜想
2.4 模拟百度spider
模拟百度爬虫至少有三种方式:
python模拟
使用第三方模拟spider网站
Chrome的UA插件
自然最省事的是用UA插件,我用的是 User-Agent Switcher - Options(小蓝色图标真好看)
查到了百度的spider的UA如下:
1 | Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html) |
很方便地加进去,然后选择该UA: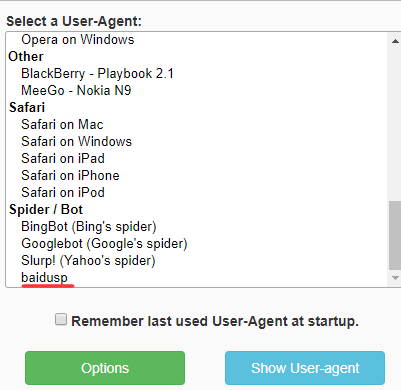
然后再次访问该页面,果然访问到了我想要看到的东西:
三、 总结
根据经验,这种手法是菠菜服务器设置根据不同的UA提供不同的内容,加一条判断+转发即可。
但这个事其实可以带来一些思考,比如说:
菠菜网站这种伪装方式虽然起到了欺骗robots的效果,但是从人的角度来讲,相当于你穿了一层机器人认不出来的衣服,但这种衣服会被熟悉的人一眼认出来,也就是有暴露特征,从技术上讲这样可能更容易被发现
这对于企业安全人员来说又是一个新的挑战,被别人穿衣服可不好受,可以针对性地检查检查有没有人在穿衣服,这些人为什么这样做,有没有办法防御?